Population Based Training¶
Background¶
Population Based Training (PBT) as introduced by Jaderberg et al. 2017 is an evolutionary algorithm for hyperparameter search. The diagram below is taken from Jaderberg et al. 2017 and gives an intuition on the algorithm. It starts with a random population of hyperparamater configurations. Each population member is trained for a limited amount of time and evaluated. When every population member has been evaluated, the ones with low scores replace their own weights and hyperparameters with those from population members with high scores (exploit) and perturb the hyperparameters (explore). Then all population members are trained and evaluated again and the process repeats. This process achieves a joint optimization of the model parameters and training hyperparameters.
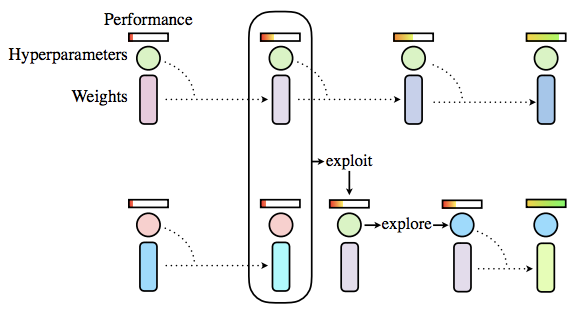
Note that only parameters can be tuned that can be changed during training. The number of layers in a neural network for example is better tuned with e.g. the GPyOpt Algorithm.
[119]:
import sherpa
import keras
from keras.models import Sequential, load_model
from keras.layers import Dense, Flatten
from keras.datasets import mnist
from keras.optimizers import Adam
import tempfile
import os
import shutil
import keras.backend as K
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import cm
%matplotlib inline
Dataset Preparation¶
Training data is normalized to the [0, 1] range.
[12]:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train/255.0, x_test/255.0
Sherpa Setup¶
We define one hyperparameter learning_rate. The algorithms uses a population_size of 5. This means the first 5 trials returned by the algorithm are randomly sampled. Each is trained by the user for say one epoch. This is the first generation. After that the 4 best out of these five are returned one after another (the top 80%). The fifth one (bottom 20%) is resampled from the top 20% (here just the best trial from generation 1) and its parameters are perturbed. For perturbation the
parameter, here the learning_rate is randomly multiplied by 0.8 or 1.2 (as defined by the perturbation_factors). After that the next generation evolves in a similar way. The algorithm stops after num_generations generations.
[102]:
parameters = [sherpa.Continuous('learning_rate', [1e-4, 1e-2], 'log')]
algorithm = sherpa.algorithms.PopulationBasedTraining(population_size=5,
num_generations=5,
perturbation_factors=(0.8, 1.2),
parameter_range={'learning_rate': [1e-6, 1e-1]})
study = sherpa.Study(parameters=parameters,
algorithm=algorithm,
lower_is_better=False,
dashboard_port=8997)
INFO:sherpa.core:
-------------------------------------------------------
SHERPA Dashboard running. Access via
http://128.195.75.106:8997 if on a cluster or
http://localhost:8997 if running locally.
-------------------------------------------------------
Make a temporary directory to store model files in. Population based training jointly optimizes a population of models and their hyperparameters. To train all models at the same time we train each model for one epoch (or more if you like), save it (using trial.parameters[‘save_to’]), and load it again at a later time when needed (using trial.parameters[‘load_from’]). For this reason, we need a directory to save these models in.
[104]:
model_dir = tempfile.mkdtemp()
Hyperparameter Optimization¶
Technically Population Based Training could go on forever, training ever more generations. In reality however we would like to stop at some point. For this reason we set a max_num_generations. You can set this to the number of epochs that you would normally train the model for. Here, we choose something small to speed up the example.
[105]:
for trial in study:
generation = trial.parameters['generation']
load_from = trial.parameters['load_from']
training_lr = trial.parameters['learning_rate']
print("-"*100)
print("Generation {}".format(generation))
if load_from == "":
print("Creating new model with learning rate {}\n".format(training_lr))
# Create model
model = Sequential([Flatten(input_shape=(28, 28)),
Dense(64, activation='relu'),
Dense(10, activation='softmax')])
# Use learning rate parameter for optimizer
optimizer = Adam(lr=training_lr)
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
else:
print(f"Loading model from ", os.path.join(model_dir, load_from), "\n")
# Loading model
model = load_model(os.path.join(model_dir, load_from))
if not np.isclose(K.get_value(model.optimizer.lr), training_lr):
print("Perturbing learning rate from {} to {}".format(K.get_value(model.optimizer.lr), training_lr))
K.set_value(model.optimizer.lr, training_lr)
else:
print("Continuing training with learning rate {}".format(training_lr))
# Train model for one epoch
model.fit(x_train, y_train)
loss, accuracy = model.evaluate(x_test, y_test)
print("Validation accuracy: ", accuracy)
study.add_observation(trial=trial, iteration=generation,
objective=accuracy,
context={'loss': loss})
study.finalize(trial=trial)
print(f"Saving model at: ", os.path.join(model_dir, trial.parameters['save_to']))
model.save(os.path.join(model_dir, trial.parameters['save_to']))
study.save(model_dir)
----------------------------------------------------------------------------------------------------
Generation 1
Creating new model with learning rate 0.0033908174916255636
Epoch 1/1
60000/60000 [==============================] - 7s 120us/step - loss: 0.2279 - acc: 0.9324
10000/10000 [==============================] - 1s 117us/step
Validation accuracy: 0.962
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/1
----------------------------------------------------------------------------------------------------
Generation 1
Creating new model with learning rate 0.00024918992981810167
Epoch 1/1
60000/60000 [==============================] - 8s 129us/step - loss: 0.4917 - acc: 0.8711
10000/10000 [==============================] - 1s 124us/step
Validation accuracy: 0.9203
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/2
----------------------------------------------------------------------------------------------------
Generation 1
Creating new model with learning rate 0.006140980350498516
Epoch 1/1
60000/60000 [==============================] - 8s 125us/step - loss: 0.2292 - acc: 0.9309
10000/10000 [==============================] - 1s 124us/step
Validation accuracy: 0.9548
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/3
----------------------------------------------------------------------------------------------------
Generation 1
Creating new model with learning rate 0.0010303357974986642
Epoch 1/1
60000/60000 [==============================] - 7s 122us/step - loss: 0.3119 - acc: 0.9096
10000/10000 [==============================] - 1s 124us/step
Validation accuracy: 0.948
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/4
----------------------------------------------------------------------------------------------------
Generation 1
Creating new model with learning rate 0.0010189099949300035
Epoch 1/1
60000/60000 [==============================] - 8s 125us/step - loss: 0.2994 - acc: 0.9150
10000/10000 [==============================] - 1s 123us/step
Validation accuracy: 0.9517
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/5
----------------------------------------------------------------------------------------------------
Generation 2
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/1 ...
Continuing training with learning rate 0.0033908174916255636
Epoch 1/1
60000/60000 [==============================] - 6s 93us/step - loss: 0.1107 - acc: 0.9669
10000/10000 [==============================] - 1s 125us/step
Validation accuracy: 0.9678
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/6
----------------------------------------------------------------------------------------------------
Generation 2
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/3 ...
Continuing training with learning rate 0.006140980350498516
Epoch 1/1
60000/60000 [==============================] - 6s 94us/step - loss: 0.1347 - acc: 0.9596
10000/10000 [==============================] - 1s 127us/step
Validation accuracy: 0.9507
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/7
----------------------------------------------------------------------------------------------------
Generation 2
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/5 ...
Continuing training with learning rate 0.0010189099949300035
Epoch 1/1
60000/60000 [==============================] - 6s 98us/step - loss: 0.1454 - acc: 0.9574
10000/10000 [==============================] - ETA: - 1s 135us/step
Validation accuracy: 0.9634
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/8
----------------------------------------------------------------------------------------------------
Generation 2
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/4 ...
Continuing training with learning rate 0.0010303357974986642
Epoch 1/1
60000/60000 [==============================] - 6s 100us/step - loss: 0.1527 - acc: 0.9558
10000/10000 [==============================] - 1s 131us/step
Validation accuracy: 0.9591
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/9
----------------------------------------------------------------------------------------------------
Generation 2
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/1 ...
Perturbing learning rate from 0.0033908174373209476 to 0.004068980989950676
Epoch 1/1
60000/60000 [==============================] - 6s 98us/step - loss: 0.1178 - acc: 0.9644
10000/10000 [==============================] - 1s 134us/step
Validation accuracy: 0.9687
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/10
----------------------------------------------------------------------------------------------------
Generation 3
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/10 ...
Continuing training with learning rate 0.004068980989950676
Epoch 1/1
60000/60000 [==============================] - 6s 99us/step - loss: 0.0897 - acc: 0.9720
10000/10000 [==============================] - 1s 137us/step
Validation accuracy: 0.9711
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/11
----------------------------------------------------------------------------------------------------
Generation 3
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/6 ...
Continuing training with learning rate 0.0033908174916255636
Epoch 1/1
60000/60000 [==============================] - 6s 101us/step - loss: 0.0837 - acc: 0.9742
10000/10000 [==============================] - 2s 150us/step
Validation accuracy: 0.9697
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/12
----------------------------------------------------------------------------------------------------
Generation 3
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/8 ...
Continuing training with learning rate 0.0010189099949300035
Epoch 1/1
60000/60000 [==============================] - 6s 108us/step - loss: 0.1054 - acc: 0.9687
10000/10000 [==============================] - 1s 148us/step
Validation accuracy: 0.9646
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/13
----------------------------------------------------------------------------------------------------
Generation 3
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/9 ...
Continuing training with learning rate 0.0010303357974986642
Epoch 1/1
60000/60000 [==============================] - 7s 111us/step - loss: 0.1112 - acc: 0.9675
10000/10000 [==============================] - 2s 155us/step
Validation accuracy: 0.9687
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/14
----------------------------------------------------------------------------------------------------
Generation 3
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/10 ...
Perturbing learning rate from 0.004068980924785137 to 0.004882777187940811
Epoch 1/1
60000/60000 [==============================] - 7s 114us/step - loss: 0.1022 - acc: 0.9686
10000/10000 [==============================] - 2s 153us/step
Validation accuracy: 0.9679
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/15
----------------------------------------------------------------------------------------------------
Generation 4
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/11 ...
Continuing training with learning rate 0.004068980989950676
Epoch 1/1
60000/60000 [==============================] - 7s 117us/step - loss: 0.0772 - acc: 0.9759
10000/10000 [==============================] - 1s 149us/step
Validation accuracy: 0.9669
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/16
----------------------------------------------------------------------------------------------------
Generation 4
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/12 ...
Continuing training with learning rate 0.0033908174916255636
Epoch 1/1
60000/60000 [==============================] - 7s 109us/step - loss: 0.0728 - acc: 0.9775
10000/10000 [==============================] - 1s 148us/step
Validation accuracy: 0.9659
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/17
----------------------------------------------------------------------------------------------------
Generation 4
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/14 ...
Continuing training with learning rate 0.0010303357974986642
Epoch 1/1
60000/60000 [==============================] - 7s 112us/step - loss: 0.0885 - acc: 0.9735
10000/10000 [==============================] - 2s 185us/step
Validation accuracy: 0.9711
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/18
----------------------------------------------------------------------------------------------------
Generation 4
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/15 ...
Continuing training with learning rate 0.004882777187940811
Epoch 1/1
60000/60000 [==============================] - 7s 118us/step - loss: 0.0862 - acc: 0.9740
10000/10000 [==============================] - 2s 151us/step
Validation accuracy: 0.968
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/19
----------------------------------------------------------------------------------------------------
Generation 4
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/12 ...
Perturbing learning rate from 0.0033908174373209476 to 0.002712653993300451
Epoch 1/1
60000/60000 [==============================] - 7s 112us/step - loss: 0.0625 - acc: 0.9806
10000/10000 [==============================] - 2s 151us/step
Validation accuracy: 0.9721
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/20
----------------------------------------------------------------------------------------------------
Generation 5
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/20 ...
Continuing training with learning rate 0.002712653993300451
Epoch 1/1
60000/60000 [==============================] - 7s 114us/step - loss: 0.0528 - acc: 0.9835
10000/10000 [==============================] - 2s 151us/step
Validation accuracy: 0.9734
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/21
----------------------------------------------------------------------------------------------------
Generation 5
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/18 ...
Continuing training with learning rate 0.0010303357974986642
Epoch 1/1
60000/60000 [==============================] - 7s 116us/step - loss: 0.0725 - acc: 0.9778
10000/10000 [==============================] - 2s 187us/step
Validation accuracy: 0.9718
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/22
----------------------------------------------------------------------------------------------------
Generation 5
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/19 ...
Continuing training with learning rate 0.004882777187940811
Epoch 1/1
60000/60000 [==============================] - 7s 114us/step - loss: 0.0784 - acc: 0.9762
10000/10000 [==============================] - 2s 166us/step
Validation accuracy: 0.9716
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/23
----------------------------------------------------------------------------------------------------
Generation 5
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/16 ...
Continuing training with learning rate 0.004068980989950676
Epoch 1/1
60000/60000 [==============================] - 7s 122us/step - loss: 0.0653 - acc: 0.9800
10000/10000 [==============================] - 2s 177us/step
Validation accuracy: 0.9679
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/24
----------------------------------------------------------------------------------------------------
Generation 5
Loading model from /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/11 ...
Perturbing learning rate from 0.004068980924785137 to 0.004882777187940811
Epoch 1/1
60000/60000 [==============================] - 7s 117us/step - loss: 0.0881 - acc: 0.9734
10000/10000 [==============================] - 2s 175us/step
Validation accuracy: 0.9663
Saving model at: /var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/25
The best found hyperparameter configuration is:
[126]:
study.get_best_result()
[126]:
{'Iteration': 5,
'Objective': 0.9734,
'Trial-ID': 21,
'generation': 5,
'learning_rate': 0.002712653993300451,
'lineage': '1,6,12,20,',
'load_from': '20',
'loss': 0.09256360807713354,
'save_to': '21'}
This model is stored at:
[107]:
print(os.path.join(model_dir, study.get_best_result()['save_to']))
/var/folders/5v/l788ch2j7tg0q0y1rt04c08w0000gn/T/tmpt_1z3upl/21
These are plots of the evolution of validation accuracy and log learning rates. Lines of equal color indicate that these belong to equal seed trials, that is they stem from the same population member from the first generation.
[125]:
completed = study.results.query("Status == 'COMPLETED'")
fig, axis = plt.subplots(ncols=2, figsize=(15, 5))
n = 5
color=cm.rainbow(np.linspace(0,1,n))
for j in range(1, n+1):
descendents = completed[(completed['lineage'].str.startswith('{},'.format(j)).fillna(False))]
for i, row in descendents.iterrows():
x = list(range(1, len(row['lineage'].split(","))+1))
obj = []
lr = []
for tid in row['lineage'].split(",")[:-1]:
obj.append(completed.loc[completed['Trial-ID']==int(tid)]['Objective'].values[0])
lr.append(completed.loc[completed['Trial-ID']==int(tid)]['learning_rate'])
obj.append(row['Objective'])
lr.append(row['learning_rate'])
axis[0].plot(x, obj, '-', color=color[j-1], linewidth=2.5)
axis[1].plot(x, lr, '-', color=color[j-1], linewidth=2.5)
axis[0].set_xlabel("Generation")
axis[0].set_ylabel("Validation Accuracy")
axis[1].set_xlabel("Generation")
axis[1].set_ylabel("Log(Learning Rate)")
axis[1].set_yscale('log')
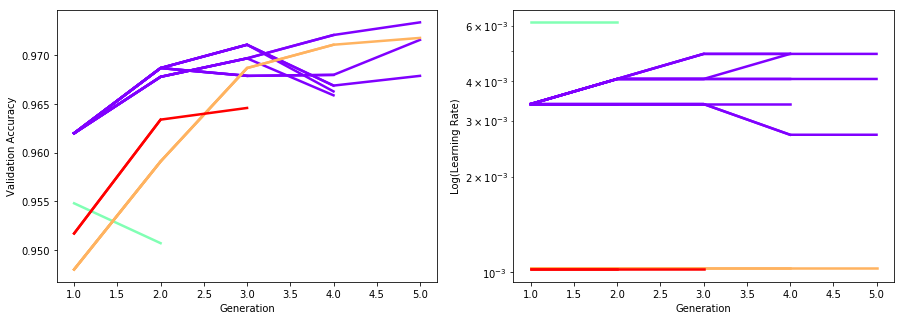
To remove the model directory:
[103]:
# Remove model_dir
shutil.rmtree(model_dir)